
🟡 Data Foundations: Preparing for Intelligent Features
A Tactical Guide to Data Quality That Powers AI You Can Trust

Imagine you’re building a smart home assistant for yourself, one that responds to your voice, learns your patterns, and helps automate your day.
Now imagine that under all that intelligence is a foundation of poor data: mislabels of information about you, missing information, mismatched formats, it mis-identifies who you are, and it is not consistent in its response.
What you get isn’t a helpful assistant. You get confusion. Misunderstandings. Maybe even harm.
Something similar actually happened. In 2024, a tech giant had to recall an AI-powered home security product after it repeatedly misidentified pets as intruders, triggering false alarms. The cause? Poor training data that failed to represent real-world edge cases.
This is not a bug in the model. It’s a failure of data readiness.
And it’s more common than you think.

Why It Matters
Data quality isn’t a side task, it’s the foundation.
Here’s the uncomfortable truth, most builders and companies are building intelligent systems on unreliable data.
And the cost is real.
Poor data quality quietly drains up to 20% of company revenue.
60% of AI project failures today are due to poor data, according to Forrester.
The average cost? $15 million per company per year.
But when data quality is treated like a product priority, the ROI flips.
A financial firm cut errors by 30% after proper profiling and cleansing.
Another boosted AI accuracy by 20% after implementing a governance framework.
Zillow’s now infamous pricing model as I read, failed due to bad data. Meanwhile, a mining company cut downtime by 25% by feeding its AI real-time, high-integrity sensor data.
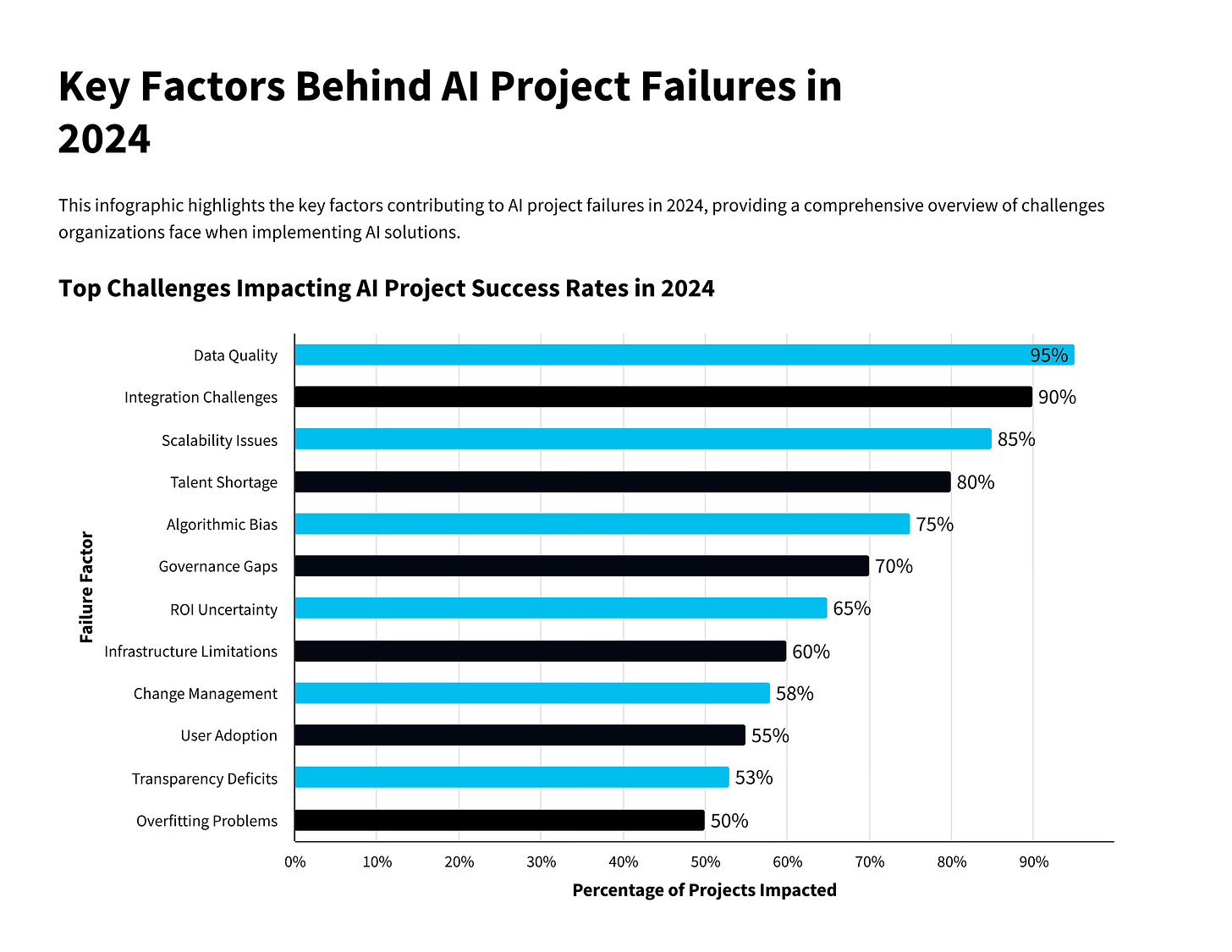
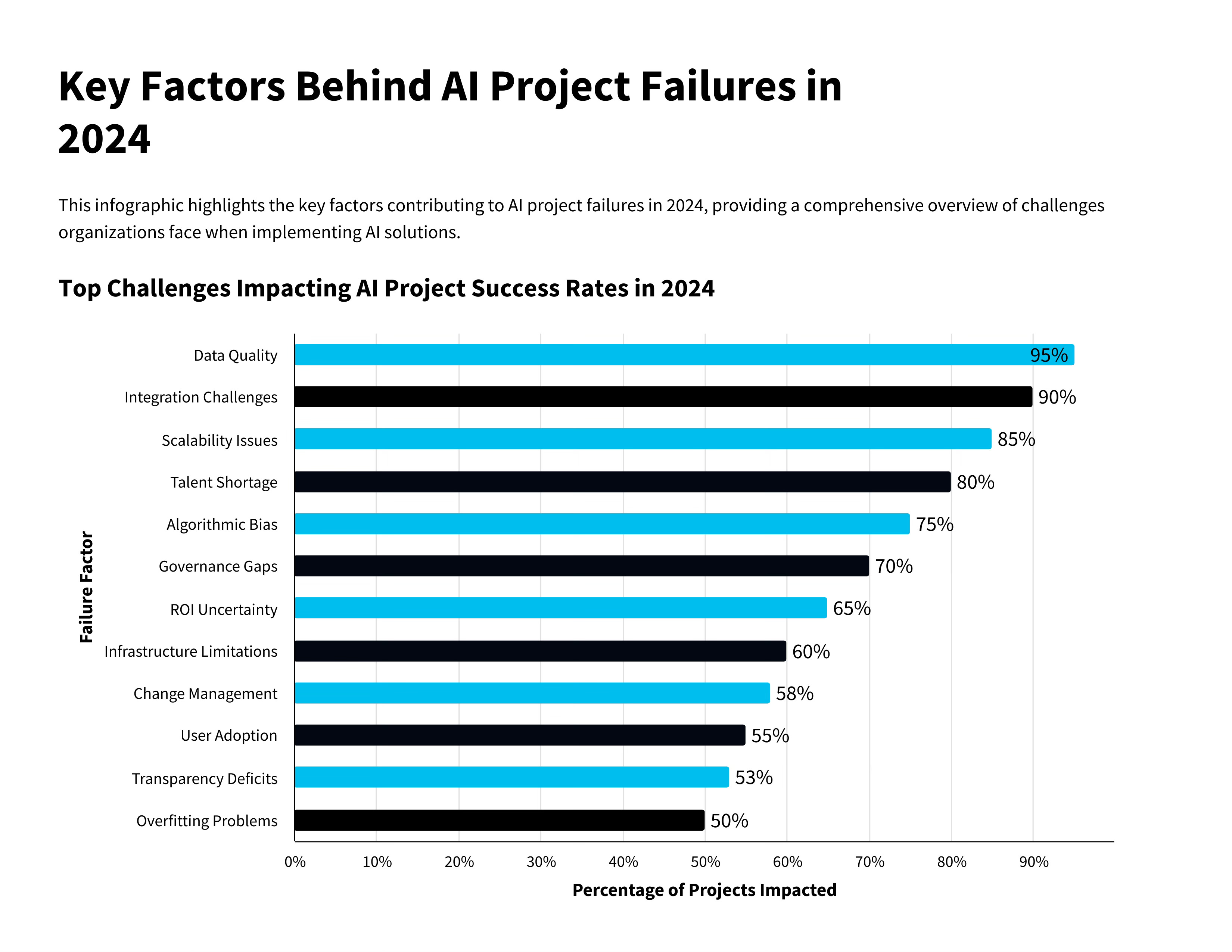
These are lesson learnt and playbook, if you want intelligence to work, your data must be an asset, not an afterthought.
Bad data derails even the best architecture. It introduces bias, reduces trust, and slows everything down.
So how do we build products that actually learn and improve over time?
We start by treating data quality as a product, not a backend task.
Checklist on How To Make Your Data AI-Ready
So, how do you make sure your data doesn’t let you down? To create a robust data foundation for AI, you need a checklist that covers every angle, governance, preparation, feature engineering, and ongoing maintenance. Here’s the breakdown, designed to be practical for both newbies and seasoned pros:
1. Data Governance and Management
Governance sets the rules for managing data as a strategic asset. Key elements include:
Establish a Governance Framework: Define roles (e.g., data stewards) and policies for consistent management. Research and report suggest this can improve data quality by 20%.
Set Quality Metrics: Track metrics around accuracy, completeness, consistency, timeliness, validity, and uniqueness to measure overall progress of data readiness and richness.
Secure Data and Ensure Privacy: Use encryption and access controls to comply with regulations like GDPR or CCPA.
Maintain Compliance: Align with legal and industry standards, especially as AI regulations tighten.
Balance Accessibility and Security: Ensure data is usable but protected and track everyone with access to PII.
Track Data Lineage: Document data origins and transformations for traceability, critical for debugging Data and AI issues.
Data Definition: Ensure all data attributes have clear definitions, tags and labelling.
Enhance Interpretability: Provide clear documentation and metadata to ensure clarity.
2. Data Acquisition and Preparation
Your AI’s training data must be sufficient, un-biased, and clean:
Ensure Sufficient Data: Aim for 10,000 records minimum, ideally 30,000, for robust training, per ServiceNow.
Verify Representativeness: Confirm data reflects real-world scenarios to avoid bias.
Profile Data: Analyze structure and content to spot issues like missing values or anomalies.
Clean Data: Correct or remove inaccurate, incomplete, or irrelevant records.
Address Class Imbalance: Use techniques like SMOTE to balance datasets or missing values for classification models or tasks.
Manage Outliers: Handle outliers, especially in regression, to prevent skewed predictions.
Standardize Formats: Ensure consistency in data types (e.g., dates, numbers).
Clean Input Fields: Remove mixed languages, special characters, or HTML tags.
Limit Distinct Values: Focus on common values for fields with many unique entries.
Use Supported Data Types: Stick to compatible types (e.g., strings, numbers).
3. Feature Engineering
Feature engineering optimizes data for AI, ensuring inputs are relevant. How do you select important and rich-enough datasets and data variables for AI model:
Select Relevant Features: Choose inputs with strong correlation to the target, using correlation analysis or feature importance scores.
Remove Redundant Features: Eliminate highly correlated or low-variability features.
Handle Missing Values: Use imputation (e.g., mean substitution) to fill gaps without bias.
Ensure Feature Consistency: Remove duplicates and inconsistencies.
Check for Bias: Scrutinize data to avoid unfair outputs, like the 2024 security system recall.
Tailor to Algorithm Needs: Prepare data for specific algorithms (e.g., normalization for neural networks).
Validate Data Suitability: Ensure data aligns with the AI’s purpose.
Ensure Clean Output Fields: Confirm the target variable is the right type and free of outliers.
4. Monitoring and Maintenance
Data quality requires ongoing effort to stay effective:
Implement Continuous Monitoring: Use tools to track quality in real-time and flag issues.
Validate Regularly: Check data against business rules for relevance and accuracy.
Conduct Audits: Periodically review processes to identify gaps.
Update Practices: Adapt to new tools and trends, like AI-driven data quality solutions, expected to be standard by 2025, per Deloitte.

Playbook: Turn Checklist Into Action
Here’s a playbook that scales:
Assess your current state: What’s broken? What’s invisible?
Create a data quality roadmap: Treat it like a sprint backlog. Outline specific actions, timelines, and responsible parties to address each checklist item.
Establish Governance: Define roles, policies, and metrics
Automate everything you can: Use Trifacta, Dataiku, dbt, or Databricks to cut manual cleanup
Train the team: Especially those closest to data entry
Monitor, then evolve: Data quality isn't a one-time setup, it’s a flywheel
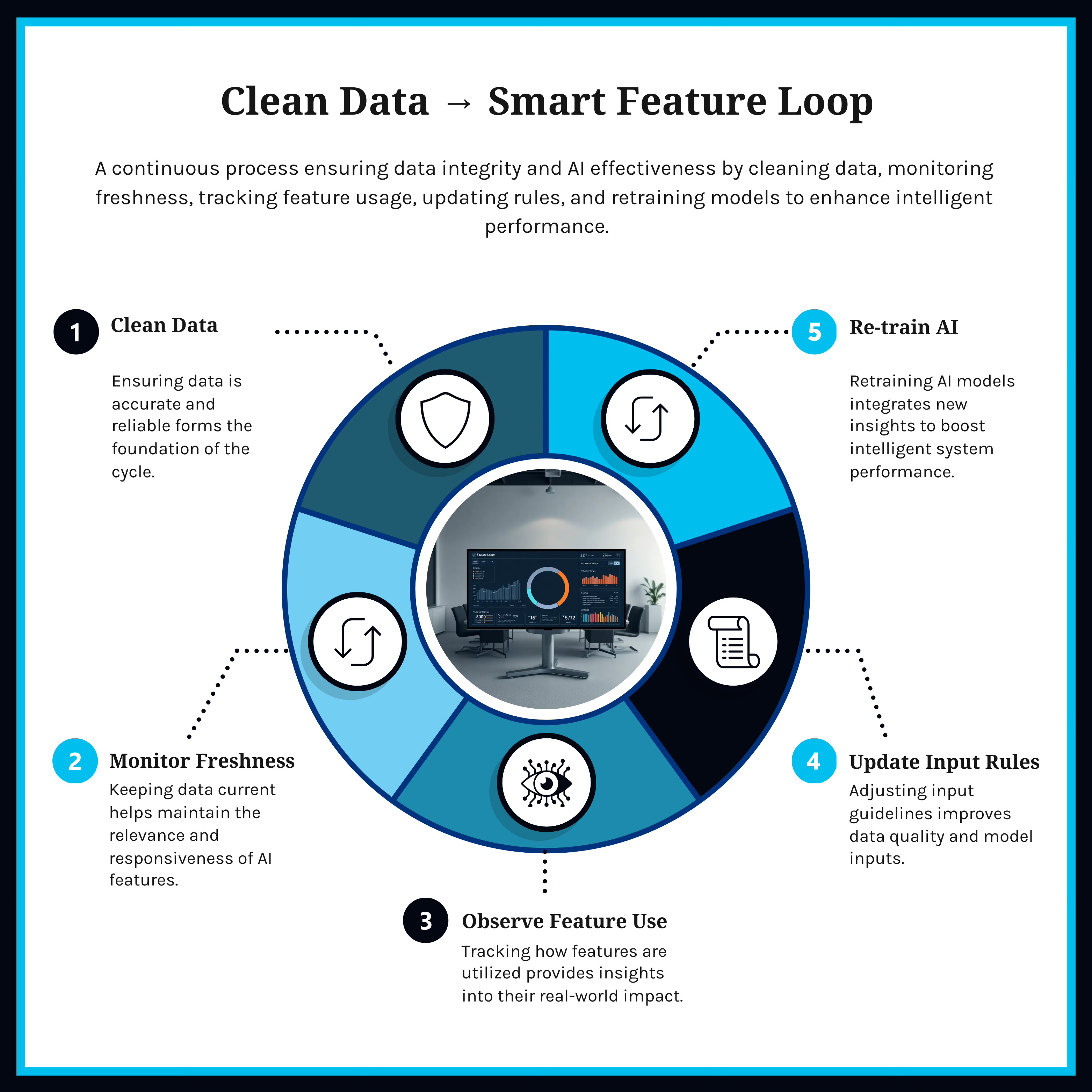
Bonus Framework: The “Clean Data → Smart Feature” Loop
Audit your most used features
Define data quality targets
Add observability + freshness alerts
Build LLMs or ML models only on verified datasets
Share lineage maps across teams
This loop becomes your feedback engine for scalable, trusted AI.
Final Thoughts
I will say don’t start with models, start with trust.
Trust in the data.
Trust in the source systems that feed it.
Trust that intelligence is only as good as its inputs.
Intelligence isn’t just about what your product can do, It’s about what your data allows it to learn.
Because data quality isn’t a nice-to-have.
It’s a product decision.
And the best time to invest in it… was yesterday.
The second-best time is your next sprint.