
From Databases to Knowledge Graphs: Why AI Is Rewriting the Architecture Playbook.
The optimistic playbook for evolving from systems of records to systems of intelligence.

For over 30 years, relational databases quietly powered the modern business world.
SQL ruled the world of analytics.
They sat behind apps, core systems, supply chains, CRMs, and BI dashboards.
SQL became a universal language for querying facts and crunching reports.
But we’re at a turning point.
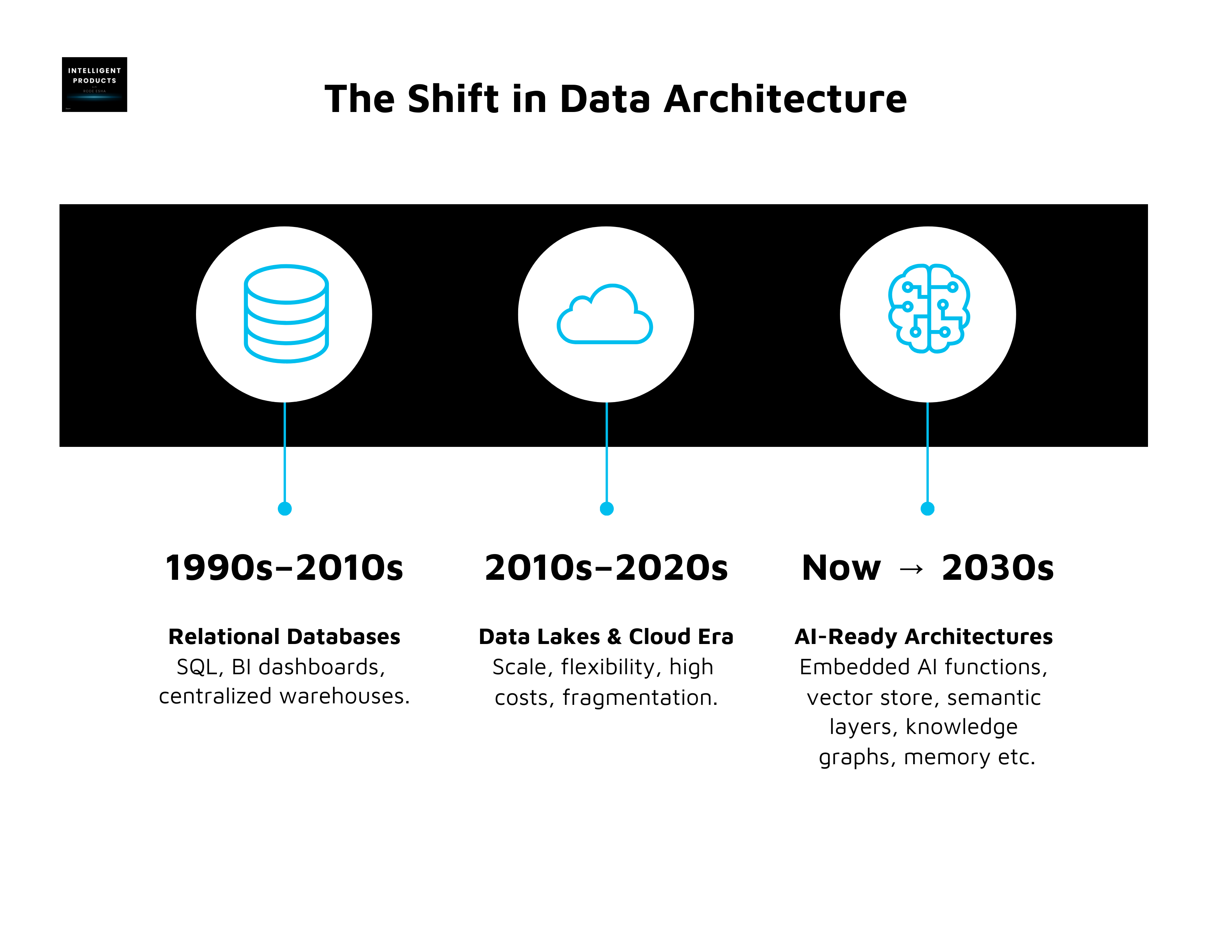
AI is changing the center of gravity in data architectures. It’s no longer just about storing information, it’s about embedding intelligence directly into the systems that run our organizations.
This shift isn’t a threat to everything we’ve built; it’s an opportunity to design architectures that are faster, more scalable, and perhaps most importantly more human.
Introduction
A panel I listened to recently raised a bold but crucial question:
Does AI fundamentally change our data architectures and the way we scale?
The consensus was clear: yes, it does. But not in the apocalyptic, “throw everything away” sense. Instead, AI nudges us toward a new playbook one that moves intelligence closer to the data, simplifies user access through natural language, and forces us to rethink silos in favor of semantic layers and knowledge graphs.
Let’s break it down.
Why It Matters
The timing couldn’t be more critical. AI adoption is accelerating, but the hidden bottleneck is almost always data architecture.
Usage is exploding. If you have 1,000 people in your organization using BI dashboards today, you could easily see 10,000+ asking natural language questions of your data once LLM-powered query tools are embedded. That scale will break fragile systems.
Cloud costs are rising. Gartner projects worldwide spending on public cloud services to grow to $679 billion in 2024 and over $1 trillion by 2027 (source: Gartner). AI workloads, especially retrieval and training only amplify these costs if efficiency is ignored.
New products are setting new expectations. Look at tools like Snowflake Cortex or Databricks Mosaic AI. Both embed vector search, model serving, and governance directly into the data platform. The platform itself is becoming intelligent, not just the apps on top of it.


Can We Unpack This?
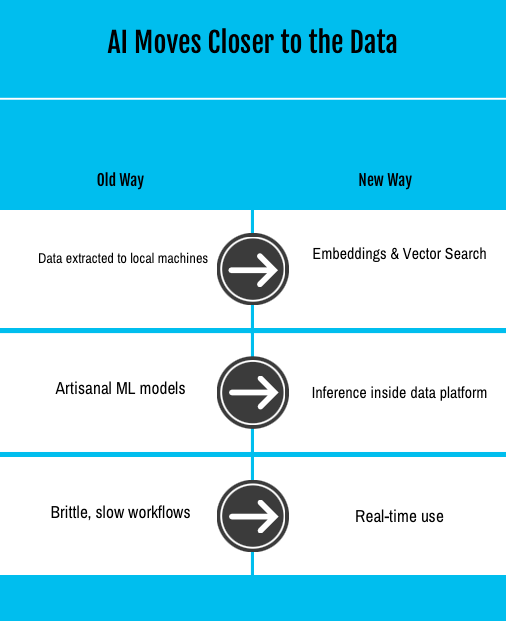
1. AI Moves Closer to the Data
Historically, machine learning lived outside the warehouse. Data scientists pulled down extracts, cleaned them locally, and trained models on isolated workbenches. That worked at small scale, but collapses when training needs terabytes of data or inference must happen in milliseconds for big organizations.
The new approach and shift is to embed training and inference functions directly inside the data platform.
Embeddings stored alongside enterprise data.
Shared feature stores accessible to all teams.
Vector search operating as a native function.
This is why you see Snowflake, Databricks, and even traditional database vendors racing to integrate ML and AI capabilities directly into their platforms.
2. The Data Foundation Problem
But simply moving AI closer to the warehouse isn’t enough. If your data is fragmented, inconsistent, and ungoverned, you’re just embedding AI into chaos.
The question on the wall is: “What does it really mean to bring AI closer to our data?”
The reality is, data consistency, reliability, and context are prerequisites. AI doesn’t replace data governance it makes it more urgent.
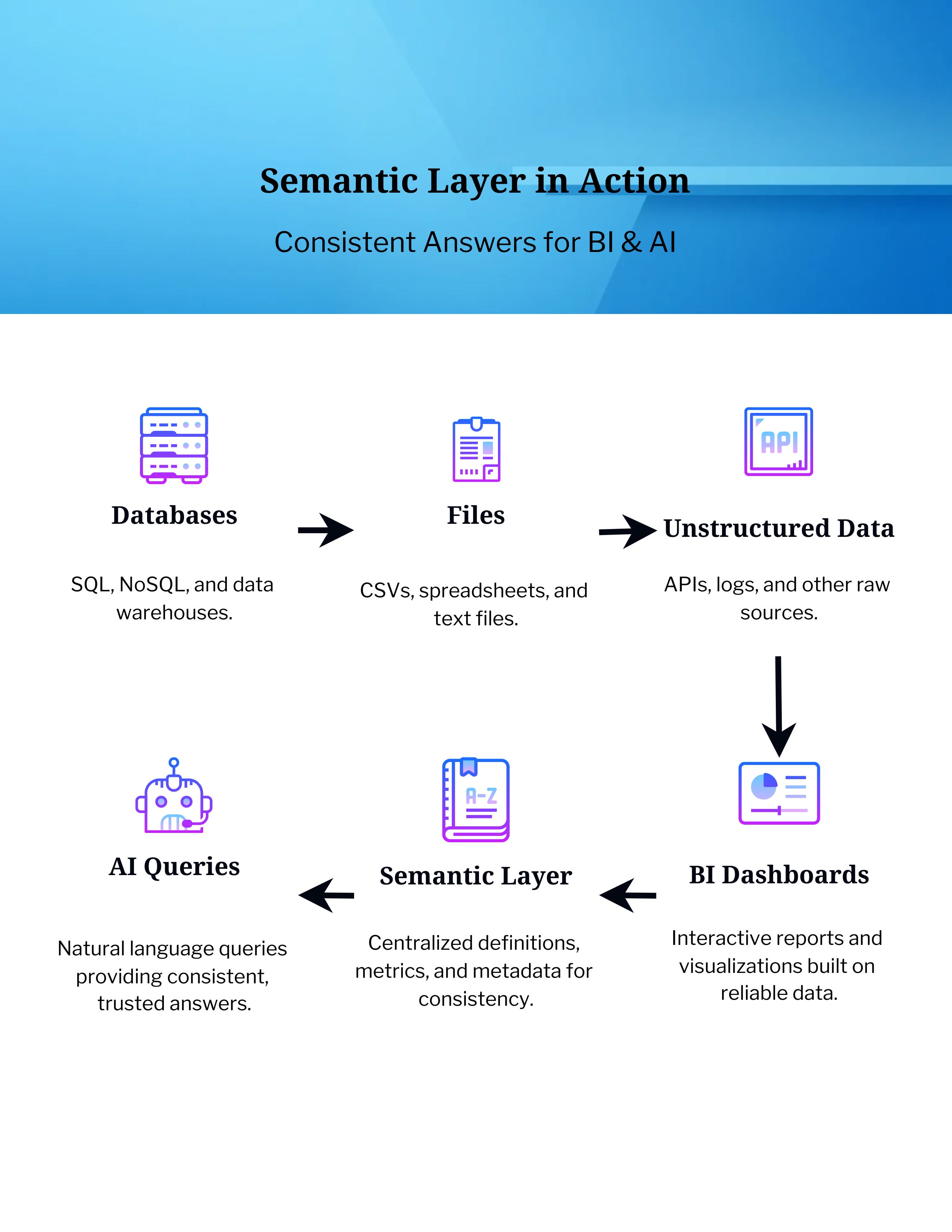
3. The Rise of the Semantic Layer
Enter the semantic layer: a shared, metadata-driven fabric that sits above your silos and gives everyone from BI dashboards to LLM queries a consistent view of the truth.
This isn’t theory. Microsoft recently announced Fabric Semantic Models as the heart of its Power BI + AI integration. Companies like AtScale and Cube are pushing similar ideas: one layer, one shared language.
The benefit? When a sales manager asks, “What’s our churn rate?” and an analyst queries the same metric in SQL, they both get the same number because it’s defined once in the semantic layer.
4. Knowledge Graphs as Connective Tissue
Graphs are re-surging as the backbone for AI-era data. Why? Because they handle relationships, context, and metadata far better than relational tables.
Think about fraud detection in fintech: a graph database like Neo4j can map relationships between accounts, transactions, and devices. Adding LLMs on top lets you query those graphs in natural language, blending structured and unstructured insights.
Or take product recommendation engines. E-commerce giants already rely on graph models to connect user behaviors, product metadata, and content embeddings. That’s how Amazon moves from “people bought this” to “you might love this.”
Graphs turn data from rows into connected knowledge, exactly what AI systems thrive on.
5. Beyond Data: Digitizing Knowledge
Perhaps the most exciting insight: data alone won’t scale AI.
Enterprises need to capture domain knowledge the unwritten expertise in people’s heads and codify it into knowledge models. These models, embedded into knowledge graphs, create the missing link between raw data and intelligent products.
Imagine a hospital system that not only stores patient records but also digitizes the tacit expertise of clinicians treatment protocols, diagnostic heuristics, safety guidelines. That knowledge, when linked with structured patient data, enables AI tools that support doctors in real-world decision-making.
6. Databricks Postgres: Building Apps on Governed Data
One of the more exciting developments here is Databricks’ launch of Postgres as a first-class service on its Lakehouse platform.
Why does this matter?
App developers now meet data where it lives. Instead of copying data from the lakehouse into separate Postgres instances, developers can build transactional and analytical apps directly against governed data in Databricks. That cuts down on duplication and accelerates time-to-market.
Governance is baked in. Because Postgres on Databricks is tied into Unity Catalog, access policies, lineage, and auditing flow seamlessly into the app layer. That’s a big step: instead of cobbling together governance across multiple systems, you get one consistent control plane.
Bridging OLTP and OLAP. Historically, app developers relied on Postgres for transactions and analysts relied on the warehouse for queries. By bringing Postgres into the lakehouse, Databricks is collapsing that gap. Apps can run on fresh, governed data while still benefiting from the scale and AI capabilities of the lakehouse.
Think of it like this: you’re building a customer-facing app that shows users their loan eligibility, personalized offers, or product recommendations. Instead of exporting features into an external Postgres DB, you can now run the app directly on Databricks Postgres. Every feature, every policy, every access rule stays consistent and every update flows in real time.
This is where governance becomes a product advantage. If a regulator asks how a recommendation was generated, you can trace lineage back through Unity Catalog without messy cross-system reconciliations.
It’s not just about building apps faster. It’s about building trustworthy intelligent products where governance, security, and context are part of the fabric.
How to Future-Proof Your Data Architecture for AI
Here’s one tactical framework that I would use to prepare for such AI design:
The AI-Ready Data Architecture Playbook
Embed intelligence where the data lives.
Use platforms that natively support embeddings, vector search, and model serving.
Example: Databricks Mosaic AI, Snowflake Cortex.
Treat efficiency as a feature.
Monitor compute spend by workload.
Implement auto-scaling and caching strategies.
Don’t let convenience bankrupt you, optimize cloud bills early.
Invest in a semantic layer.
Define core business metrics once.
Roll them out across BI dashboards, APIs, and AI queries.
This ensures consistency and trust in outputs.
Adopt knowledge graphs for context.
Start with metadata: relationships between entities, definitions, and lineage.
Expand into domain-specific models that capture expertise.
Tools that can help are Neo4j, Stardog, TigerGraph.
Digitize domain expertise.
Interview subject matter experts.
Translate unwritten processes into reusable knowledge models.
Integrate with AI systems to augment, not replace human decision-making.

My Closing Thoughts on This
Here’s the optimistic view:
AI isn’t tearing down decades of work in databases, warehouses, or BI. It’s building on them, asking us to evolve from systems of record to systems of intelligence.
Relational databases gave us order.
Data lakes gave us scale.
Semantic layers and knowledge graphs are giving us context and meaning.
For builders, it means new tools and responsibilities. For leaders, it means balancing innovation with efficiency. For users, it means finally interacting with data in plain language, not SQL.
The future is the next chapter in the story of intelligent products and one where scale, context, and human knowledge finally meet.