
The Data Quality Playbook for AI
Why AI Fails Without Data You Can Trust

If you’re like me, digging into the world of data and AI, you know that all the flashy models and algorithms mean nothing without solid data underneath. I’ve been thinking about this a lot lately, especially now, in 2025 and I have made several post on this, when AI is powering everything from chatbots to predictive analytics.
Poor data quality is like building a skyscraper on quicksand foundation: it might look impressive, but it won’t last.
So today, I’m sharing my take on “The Data Quality Playbook for AI” a practical guide built from real experiments, hard lessons, and a lot of late nights. Think of this as my cheat sheet, written like we’re catching up over coffee.

Fresh Off the Press: Why So Many AI Projects Are Crashing
Just this month, August 2025, MIT released their State of AI in Business 2025 study, and it’s sobering: 95% of generative AI pilot projects fail to deliver real value. Billions are being spent, yet most efforts stall out because companies skip the hard stuff, like validation on customer’s need, the full integrations, change management, and yes, data quality.
This isn’t new. Gartner has long reported that 85% of AI models fail due to poor or irrelevant data, which I have cited in my previous posts. RAND put the figure at 80%, double the failure rate of regular IT projects. And here’s the kicker: up to 87% of AI projects never even make it to production, with bad data as the leading culprit.
It’s a brutal reminder that hype doesn’t deliver results, strong data foundations do.
Why Data Quality is the Unsung Hero of AI
Here’s the truth, data quality isn’t just about “clean” data, it’s about data you can actually trust. That means it’s accurate, complete, consistent, timely, and relevant to the problem you’re solving.
Bad data creates biased models, faulty predictions, compliance risks, and sometimes ethical nightmares. Recent studies peg the global cost of bad data in the trillions. And with AI amplifying everything, those errors don’t just stay small, they scale.
Here’s what’s exciting, though: AI is now being used to fix data quality. Automated anomaly detection, enrichment, and validation are real game-changers. When you train a model on strong data, you don’t just get better accuracy, you save costs, build user trust, and actually ship something sustainable.
My Personal Grind: Turning Messy Data into AI Gold
A quick story. Earlier this year, I started building a custom AI model that can understand structured and unstructured data and can respond to my questions intelligently. I assumed the hard part would be tweaking open-source models. Wrong. Eighty percent of my work was data parsing, cleaning, validations and structuring.
I had code snippets, logs, and notes scattered everywhere duplicates, inconsistencies, gaps. I wrote scripts to scrub the mess, standardize formats, fill holes and reorganize into a clean schema. It was tedious. But once the data was solid, everything downstream was easy. Training the model was seamless. Prototyping was fast. And the results were actually useful after series of noisy hallucinations.
The lesson I learnt was that Data readiness is king. Address it early, and everything else runs smoother. Also, I believe as part of Governance framework we should have a solid Definition of Data Ready (DODR) or Definition of AI Ready (DOAR) like we have have a Definition of Done and Definition of Ready in Agile Software development practice
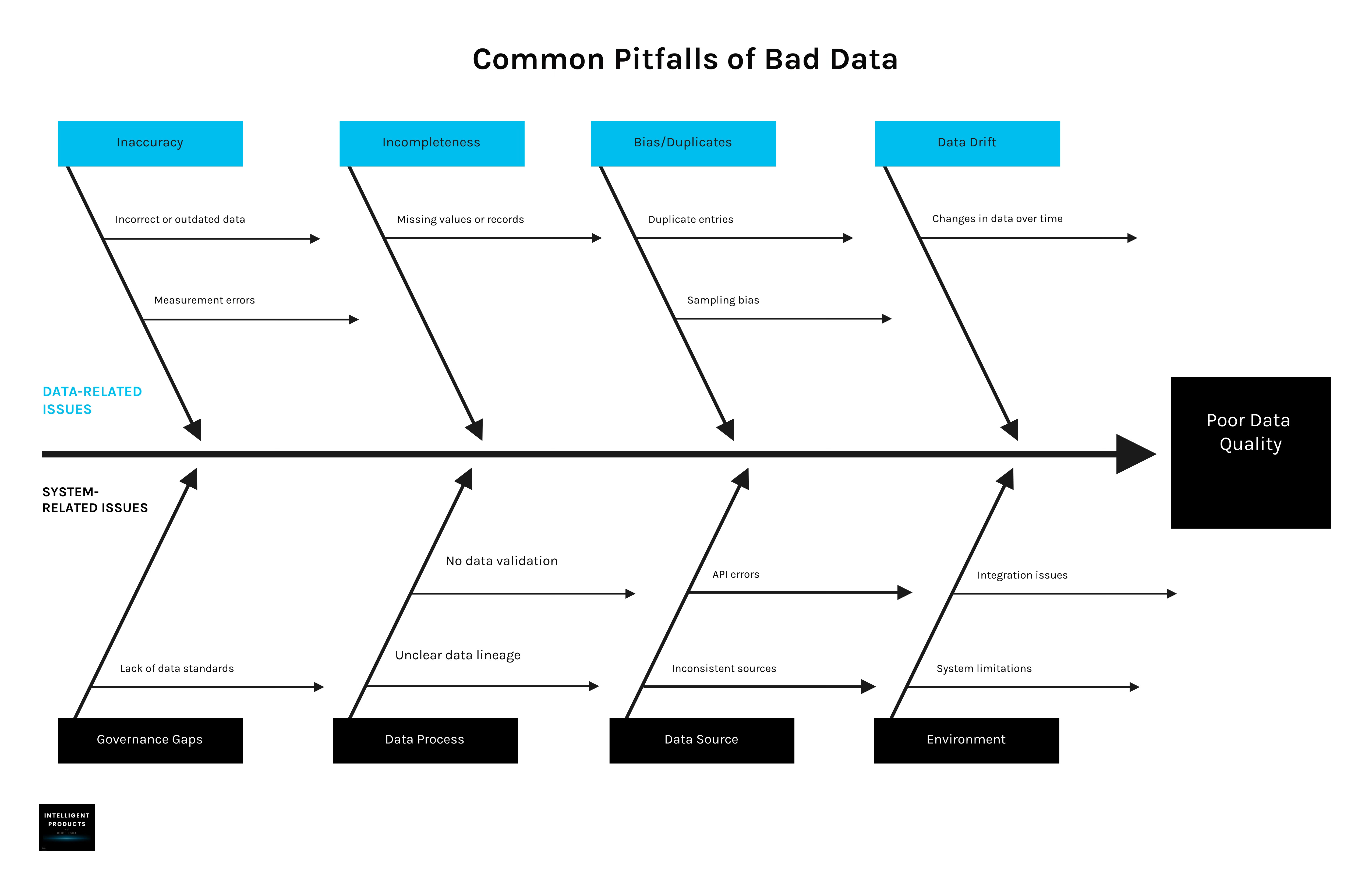
Common Pitfalls: What Goes Wrong
Here are the red flags I’ve run into (and seen others hit):
Inaccuracy & Incompleteness – Wrong or missing values lead to bad predictions
Bias & Duplicates – Skewed or repeated data creates unfair, distorted models
Data Drift – Real-world changes from data sources make your model obsolete if you’re not monitoring
Scalability Issues – Manual checks don’t cut it when your data volumes explodes, it leads to more manual work and quality debt
Data Governance - Skipping the guiding principles, reviews and checks for data quality, this is like breaking the law of data. Once you have a ready data, you will be more confident in your AI output
It is important to profile your data, look at completeness, accuracy, uniqueness. If something feels off, fix it before your model ingests it.
Your Step-by-Step Playbook
Here’s my five-step process for getting data AI-ready:
Assess & Profile – Understand what you’ve got. Understand the characteristics of your data, build a baseline report (error rates, completeness, uniqueness). Automate audit dashboards to track drift on your data assets.
Clean & Standardize – Deduplicate, normalize, fill in gaps intelligently. Mitigate bias by diversifying sources and using fairness checks for a balance dataset.
Implement Governance (Data and AI)– Add validation at the source. Define ownership (data stewards, or even bots). Track lineage so you know where your data came from and where it is going and why.
Definitions & Documentations - Create and maintain a catalog of your data with definitions, tags on schemas, tables and columns.
Monitor Continuously – Real-time anomaly detection, scheduled batch audits, predictive quality alerts, will save you some worrying and make you more proactive. Don’t treat cleaning as a one-off, setup observability, monitoring and alert (OMA)
Test & Iterate – Validate with holdouts, A/B test on refined data, feed corrections back into training for AI models. Build feedback loops into the workflow.
For unstructured data (which is most of what we deal with), use metadata and AI enrichment to make it manageable.

Tools That Actually Help
Here are the tools I’ve found most useful, mainly the ones I’m personally familiar with in Databricks and Python:
Databricks + Unity Catalog – Governance, lineage, and fine-grained access control.
Databricks Delta Live Tables + Expectations – Pipelines with built-in quality rules and quarantine for bad records.
Databricks LakeFlow (Emerging) – Aims to simplify ingestion, transformation, and orchestration with connectors.
Great Expectations – Open-source testing framework that works well with Databricks pipelines.
Pandas Profiling / ydata-profiling – Quick data profiling and exploratory reports in Python.
Python Packages:
pydeequ– Spark-based validation, integrates with Databrickscerberus– Lightweight schema validationpydantic– Enforces types and validations, great for APIs and ML inputsmarshmallow– Flexible serialization and validation
Together, they can provide coverage for profiling, validation, governance, and monitoring without overcomplicating the stack.
On the cutting edge, people are buzzing about FractionAI, a decentralized setup that rewards users for verifying data quality in real time. I am not sure about this, but worth keeping an eye on, especially for web3 lovers.
Wrapping Up
The big lesson for me is: prevention is better than cure.

That’s my playbook for turning data quality into an AI advantage. It’s not glamorous, but it’s the difference between projects that deliver and projects that fail in pilot.
Thanks for reading. If this was useful, share it with someone wrestling with AI data issues. And if you’ve got your own horror stories or lessons, hit reply, I’d love to hear them.
Until next time, keep your data clean and your AI sharp.