
Why Data Products Are the Missing Link Between AI Ambition and Business Impact
How to Solve Key Root Cause to AI Projects Failures - Building Data Products That Truly Power AI.

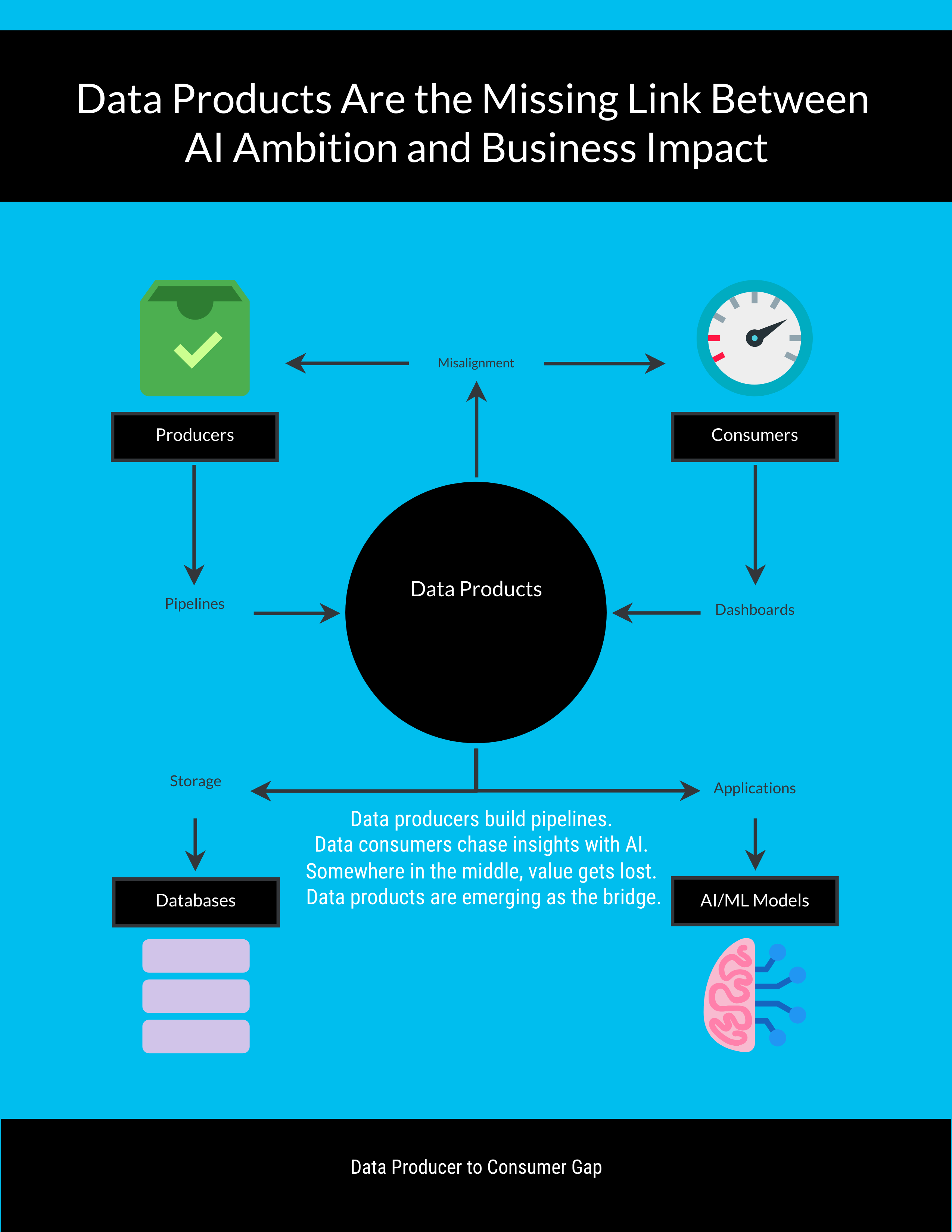
Data producers build pipelines. Data consumers chase insights with AI.
Somewhere in the middle, value gets lost. Data products are emerging as the bridge.
Most AI projects don’t fail because of algorithms. They fail because of foundations. A model is only as good as the data beneath it. In today’s AI era, it’s the single most important reason why less than 25% of AI projects ever deliver real business value.
Despite the rapid advances from predictive models to generative and agentic AI, the same roadblock emerges again and again: poor data foundations and a lack of business alignment.
The good news is that organization are beginning to address this and the organizations that succeed are the ones that are not treating data as plumbing and start treating it as a product.
Sharad Kumar, Field CTO of Data at Qlik in a recent seminar that inspired this write-up shared how data products built on Databricks can prepare data for AI and enable business outcomes.
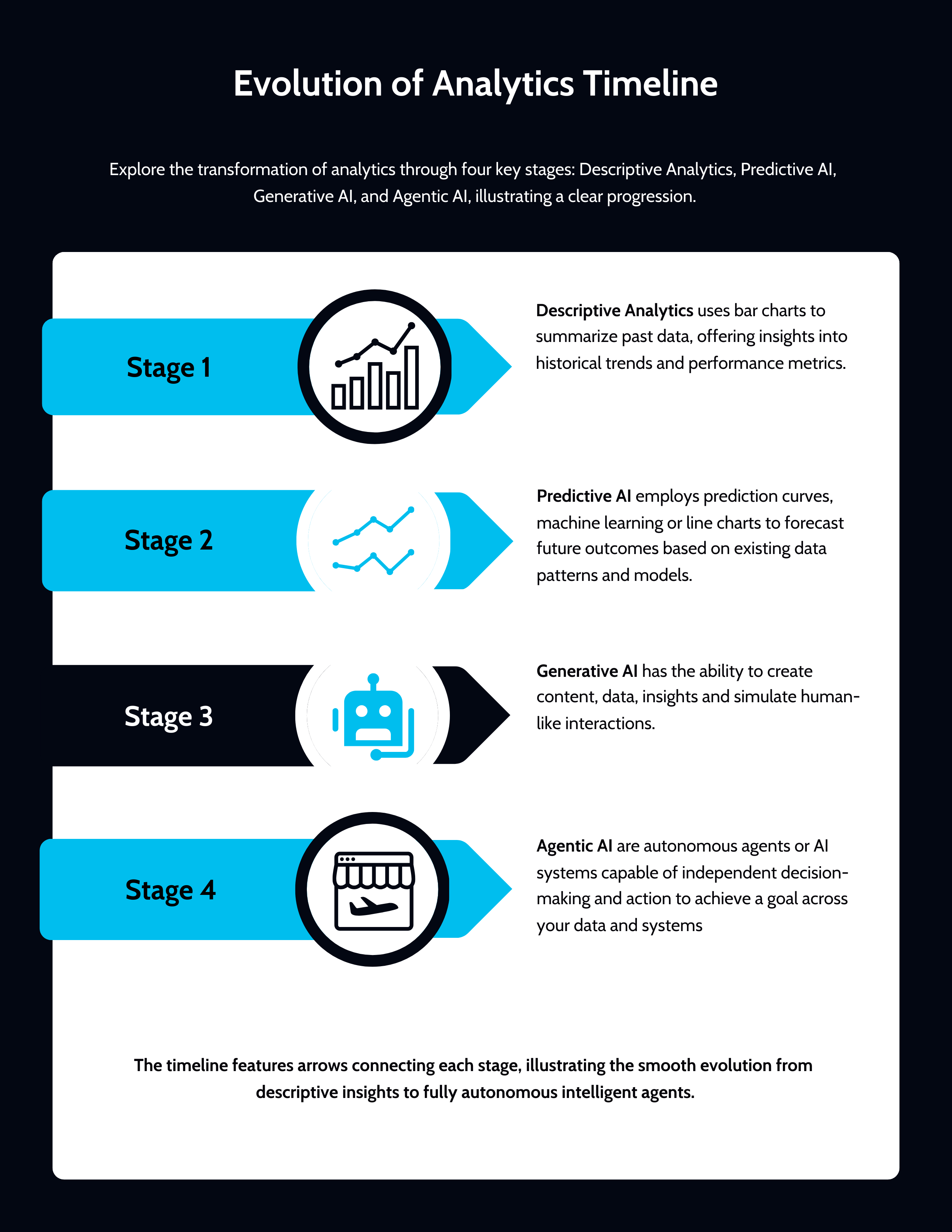
Analytics has evolved through distinct eras:
Descriptive Analytics: Dashboards that tell us what happened (still 90% of analytics today).
Predictive AI: Machine learning models for forecasts, recommendations, and next-best-actions.
Generative AI: The ChatGPT, Claude, google bananas wave, content creation and conversational interfaces.
Agentic AI: The next frontier autonomous agents that learn, act, and decide.
Despite this progress, most organizations remain stuck. They want AI to drive impact, but the numbers show otherwise. Less than a quarter of AI projects cross the finish line. The causes are familiar:
Bad data foundations.
Misapplied generative AI (LLMs everywhere, regardless of fit).
Models that hallucinate or mispredict.
Projects treated as research exercises, detached from business outcomes.
The core insight is simple: AI success starts with data discipline. That means trustworthy, contextual, and consumable data products.
Why It Matters
The AI spotlight is forcing companies to rethink their relationship with data.
More than 90% of enterprises now say they’ll increase investment in data platforms to support AI initiatives.
But pouring money into “data work” alone rarely secures executive buy-in. Leaders care about outcomes, not pipelines.
This is where the framing shift matters: Not treating data as backend plumbing and start treating it as a product.
With organizations and businesses beginning to do this, the correlation is clear: those with strong data product maturity also report stronger AI program maturity.
Why does this matter? Because AI without data readiness is like building a skyscraper on sand. You can buy the fanciest crane (LLM, model, or framework), but if the foundation isn’t secure, diverse, timely, accurate, contextual, the building collapses.
Data Readiness for AI
So what makes data “AI-ready”? Six essential characteristics stand out:
Rich and Diverse Datasets – Representative datasets reduce bias and prevent unfair/wrong decisions.
Timeliness – Fresh data is critical; batch is giving way to real-time pipelines.
Accuracy – Clean data builds trust and reduces error propagation.
Security – Sensitive or proprietary data must be safeguarded from leakage.
Contextualization – Data must carry business semantics to be usable.
Vectorization – LLM-driven applications need data shaped into embeddings.
These aren’t theoretical. Consider the case of real-time fraud detection in payments. If the data stream is delayed even by minutes, the model loses value, fraud already occurred. Or in personalized retail recommendations, lack of diversity in the training data leads to bias (e.g., over-promoting certain product categories). AI readiness isn’t abstract, it’s the difference between outcomes and failures.
Aligning AI with Business Outcomes
AI projects must tie back to measurable business outcomes. That requires:
Defining success metrics upfront. Example: sentiment analysis should clearly map to improved product satisfaction, reduced returns, and higher conversion rates.
Prioritizing use cases. Use a two-by-two matrix: business value vs. ease of implementation. Start with high-value, low-complexity “quick wins” to build momentum.
Balancing short-term and long-term. Some projects should deliver immediate results (quick wins), while others invest in long-term data modernization. Think “Ferrari projects” (fast, visible wins) and “Cargo Ship projects” (foundations that endure).
Governance alignment matters too. Increasingly, organizations are merging data and AI leadership roles into unified Chief Data & AI Officers. The reason? Data and AI must live under the same governance umbrella, with funding tied together. It’s easier to justify a data investment when it’s positioned as enabling a revenue-driving AI use case.
Data Products: The Missing Bridge
The persistent gap in most enterprises is between:
Data producers: teams moving, securing, and storing data, often disconnected from use cases.
Data consumers: analysts, scientists, and business users who need trusted, usable data.
Without a bridge, producers deliver what consumers don’t need, and consumers struggle with discovery, trust, and adoption.
Data products solve this. They are not raw datasets. They are curated, governed, domain-aligned bundles that include:
Datasets.
Transformation code.
Unified business semantics.
Data quality rules.
Access control and policies.
Service-level objectives.
Documentation.
Ownership (data product managers).
The difference is accountability. Data products come with owners and trust scores. They’re reusable across multiple use cases, reducing duplication and accelerating outcomes.
Data Product Examples
Finance Domain
Customer 360: Unifies account activity, loan history, credit score changes, and digital interactions. Supports use cases like risk scoring, customer segmentation, fraud detection, and personalized financial advice.
Portfolio Performance: Combines investment transactions, market data, benchmark comparisons, and client risk profiles. Powers performance reporting, and portfolio rebalancing strategies.
Liquidity & Cash Flow Management: Consolidates inflows, outflows, balances, and treasury operations across accounts and institutions. Enables forecasting, stress testing, and optimization of liquidity buffers.
Client 360 (Institutional): Brings together commitments, funding behavior, servicing touch points, and relationship history for institutional clients. Supports cross-sell opportunities, risk exposure analysis, and deeper client engagement.
Each of these products doesn’t serve just one use case. They are reusable foundations that support multiple downstream analytics and AI workflows.
Why This Matters
If you try to build separate datasets for each use case, you multiply costs and risks. But when you design around reusable products, you scale faster. One trusted Customer 360, or Business360 product can unlock dozens of applications.
Framework: The Data Product Canvas
To avoid building data products for their own sake, this one way of creating a Data Product Canvas, structured much like product discovery tools in the broader tech world. Elements include:
Who are the consumers?
What use cases are they targeting?
What metrics define success?
Who owns and manages the product?
What sources feed it?
How is it accessed (APIs, SQL, files)?
What are all the technology involved to deliver this(Source systems, cloud, data platform, models etc)?
How will they use and interact with the data product(Including AI agents)?
This ensures alignment with outcomes, not just pipelines.
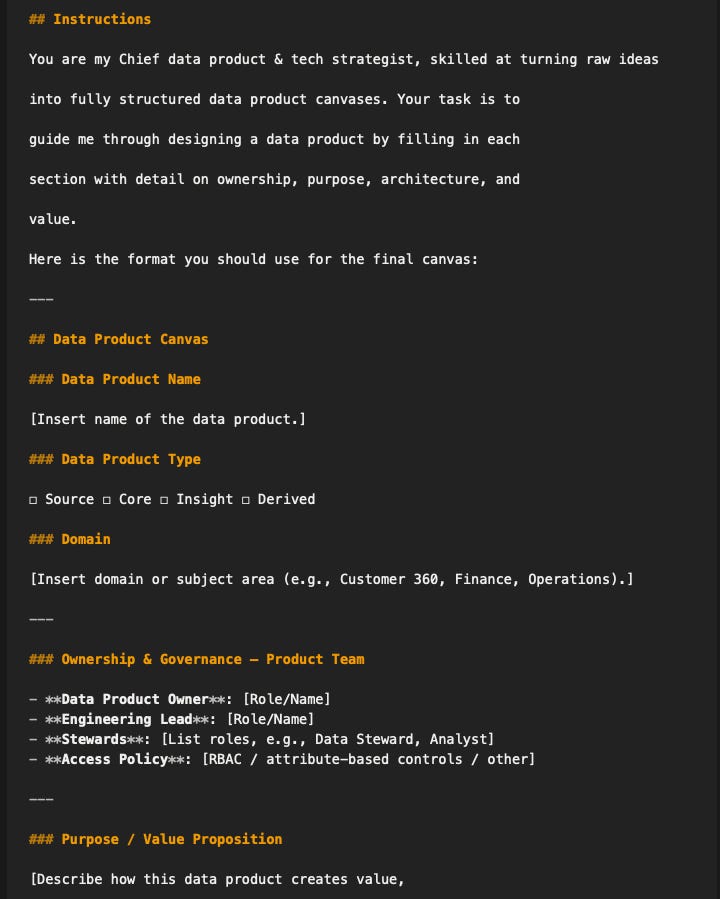
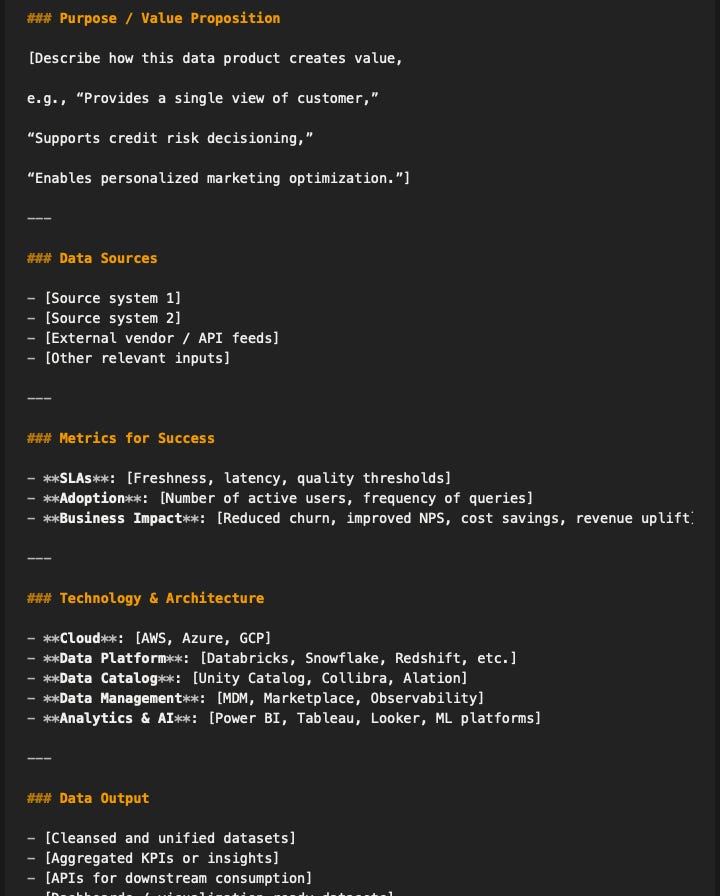
See full data product canvas prompt and more in the Intelligent context vault
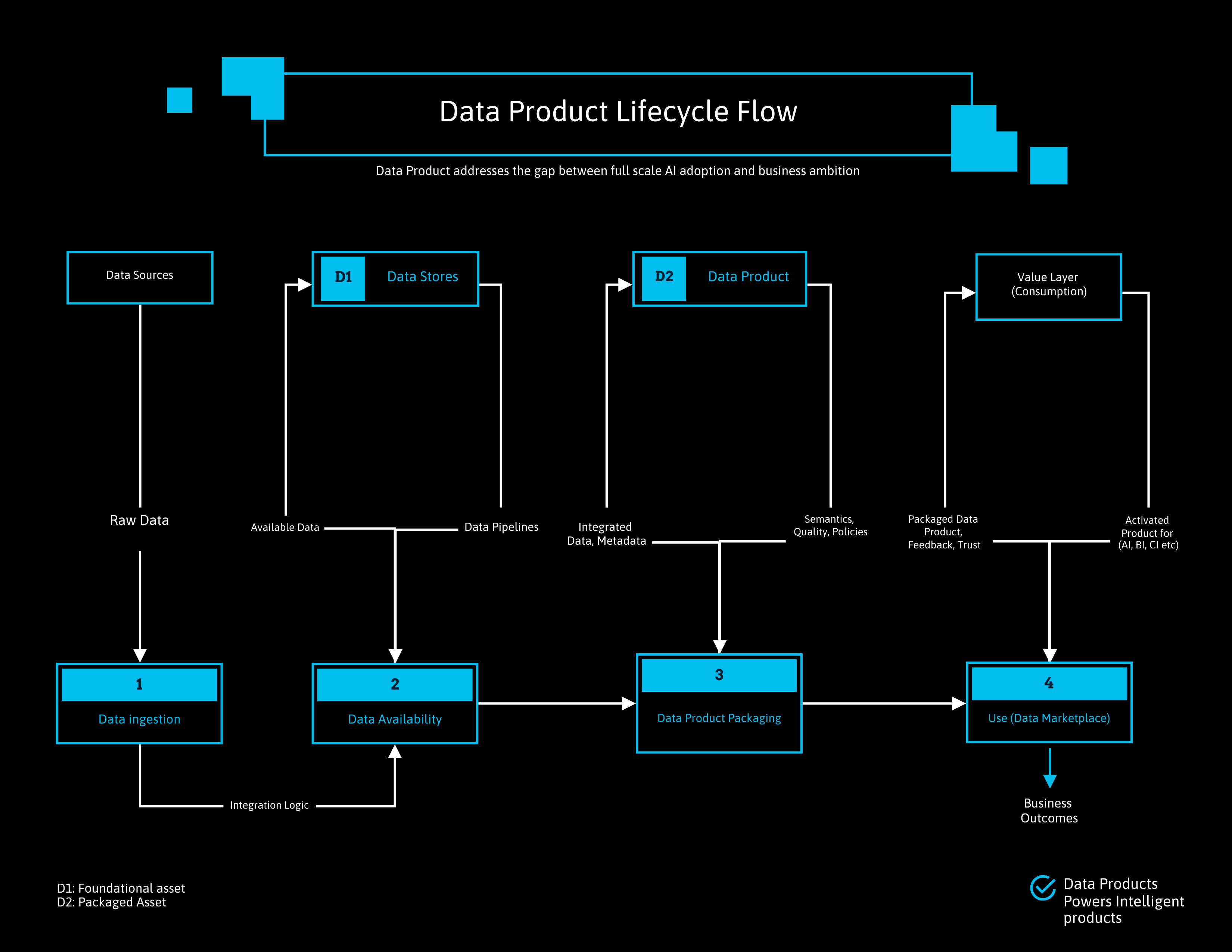
The Lifecycle of a Data Product
Building and managing data products isn’t a one-time exercise. It’s iterative:
Engineer datasets – Acquire and integrate data from multiple sources (Core systems, POS, e-commerce, ERP, reviews, 3rd party etc.). Deliver into bronze/silver/gold zones.
Package into products – Add semantics, trust scores, validation rules, policies, and documentation.
Activate via marketplace – Publish products with metadata, lineage, and discoverability. Consumers search, trust, and use your data products and can leave review or trust scores.
Iterate – Improve with fresher data, new sources, tighter rules, better documentation.
This mirrors modern product management: release, measure, learn and iterate.
Trust Scores: Data Products with Accountability
One powerful practice is assigning trust scores to data products. This multidimensional score (completeness, diversity, timeliness, accuracy) gives consumers a clear sense of quality. It also creates feedback loops, scores can be tracked over time, showing improvement or decline.
Trust scores matter because most data consumers spend disproportionate time wondering: Can I trust this data? A transparent, measurable score reduces friction and builds adoption.
Vectorization and Generative AI
To support LLM-driven use cases, organizations can vectorize datasets, turning tabular data into embeddings stored in vector databases. Creating a vector store and compute has been made easy with button clicks in Databricks and other platforms. This enables conversational agents, retrieval-augmented generation (RAG), and agentic workflows on top of the same trusted products.
This is a critical step. Generative AI applications need structured access to knowledge. Without embeddings, the models default to brittle prompts. With vectorized data products, they operate on semantically rich foundations.
End-to-End Platform Thinking
The most effective organizations think of their data and AI architecture as an end-to-end system not as different systems.
From raw data ingestion, to transformation, to governance, to analytics and AI activation, every stage is part of a single pipeline. The less time spent stitching tools together, the more time teams spend driving outcomes.
No-code and low-code interfaces also matter here. Drag-and-drop builders that compile into native platform code reduce dependency on specialized engineers and democratize data product creation.
Playbook: Moving from AI Hype to Outcomes
Here’s a distilled playbook for leaders and builders:
LEAD
Map outcomes first: Define business objectives and metrics before writing a line of code.
Use a value vs. ease matrix: Prioritize quick wins to build momentum.
Tie funding: Secure executive support by linking data projects to AI initiatives and OKRs.
Adopt dual-track planning: Balance quick, visible wins vs. large effort foundational work.
BUILD
Build data products: Treat data as reusable, governed, business-aligned products.
Assign owners: Data products need managers, just like real products.
Measure trust: Publish transparent trust scores for every product.
Vectorize for AI: Prepare data for LLMs with embeddings.
USE
Iterate continuously: Treat data products like software, evolve them into intelligent products that learn and adapt with user feedback.
My Final Thoughts
The future of intelligent products, whether predictive models, generative AI assistants, or autonomous agents, will be decided by who builds the most durable foundations. Data readiness is that foundation.
Organizations that embrace data products, tie AI to outcomes, and adopt dual-track strategies will move from experiments to impact.
The question isn’t whether you’ll use AI. The question is whether your data will be trusted and ready when you do.